Machine Learning Visualization Missing Values
Visualizing Missing Data: A Step-by-Step Guide
Handling missing data is crucial in data analysis and machine learning. Visualizing missing data helps to understand the extent and pattern of missingness, which can inform the choice of strategies for dealing with it. In this guide, we'll use Python and the missingno library to visualize missing data in a dataset.

You can download the Jupiter notebook of the example Visualizing Missing Data
1. Importing Libraries
First, we need to import the necessary libraries for data manipulation and visualization.
import pandas as pd
import numpy as np
import missingno as msno- Pandas: A powerful data manipulation library.
- NumPy: A fundamental package for numerical computations.
- Missingno: A library for visualizing missing data.
2. Loading the Data
We load the dataset into a Pandas DataFrame. For this example, we'll use a dataset that comes with the missingno library.
Same data that we used in the previous article Machine Learning Handling Missing Values. You can download the dataset from the Kaggle website
sf_permits = pd.read_csv("./Building_Permits.csv")
sf_permits.head()/tmp/ipykernel_50336/2707110962.py:1: DtypeWarning: Columns (22,32) have mixed types. Specify dtype option on import or set low_memory=False. sf_permits = pd.read_csv("./Building_Permits.csv")
Output:
| | Permit Number | Permit Type | Permit Type Definition | Permit Creation Date | Block | Lot | Street Number | Street Number Suffix | Street Name | Street Suffix | ... | Existing Construction Type | Existing Construction Type Description | Proposed Construction Type | Proposed Construction Type Description | Site Permit | Supervisor District | Neighborhoods - Analysis Boundaries | Zipcode | Location | Record ID | | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | | 0 | 201505065519 | 4 | sign - erect | 05/06/2015 | 0326 | 023 | 140 | NaN | Ellis | St | ... | 3.0 | constr type 3 | NaN | NaN | NaN | 3.0 | Tenderloin | 94102.0 | (37.785719256680785, -122.40852313194863) | 1380611233945 | | 1 | 201604195146 | 4 | sign - erect | 04/19/2016 | 0306 | 007 | 440 | NaN | Geary | St | ... | 3.0 | constr type 3 | NaN | NaN | NaN | 3.0 | Tenderloin | 94102.0 | (37.78733980600732, -122.41063199757738) | 1420164406718 | | 2 | 201605278609 | 3 | additions alterations or repairs | 05/27/2016 | 0595 | 203 | 1647 | NaN | Pacific | Av | ... | 1.0 | constr type 1 | 1.0 | constr type 1 | NaN | 3.0 | Russian Hill | 94109.0 | (37.7946573324287, -122.42232562979227) | 1424856504716 | | 3 | 201611072166 | 8 | otc alterations permit | 11/07/2016 | 0156 | 011 | 1230 | NaN | Pacific | Av | ... | 5.0 | wood frame (5) | 5.0 | wood frame (5) | NaN | 3.0 | Nob Hill | 94109.0 | (37.79595867909168, -122.41557405519474) | 1443574295566 | | 4 | 201611283529 | 6 | demolitions | 11/28/2016 | 0342 | 001 | 950 | NaN | Market | St | ... | 3.0 | constr type 3 | NaN | NaN | NaN | 6.0 | Tenderloin | 94102.0 | (37.78315261897309, -122.40950883997789) | 144548169992 |
5 rows × 43 columns
3. Matrix Plot
The matrix plot visualizes missing data by representing data points with vertical bars. Each bar shows the presence (white) or absence (black) of data points.
msno.matrix(sf_permits)Output:

Why is it important? The matrix plot helps identify patterns in the missing data, such as whether missingness occurs at random or follows a specific pattern.
4. Bar Plot
The bar plot shows the number of non-missing (present) data points for each column.
msno.bar(df)Output:
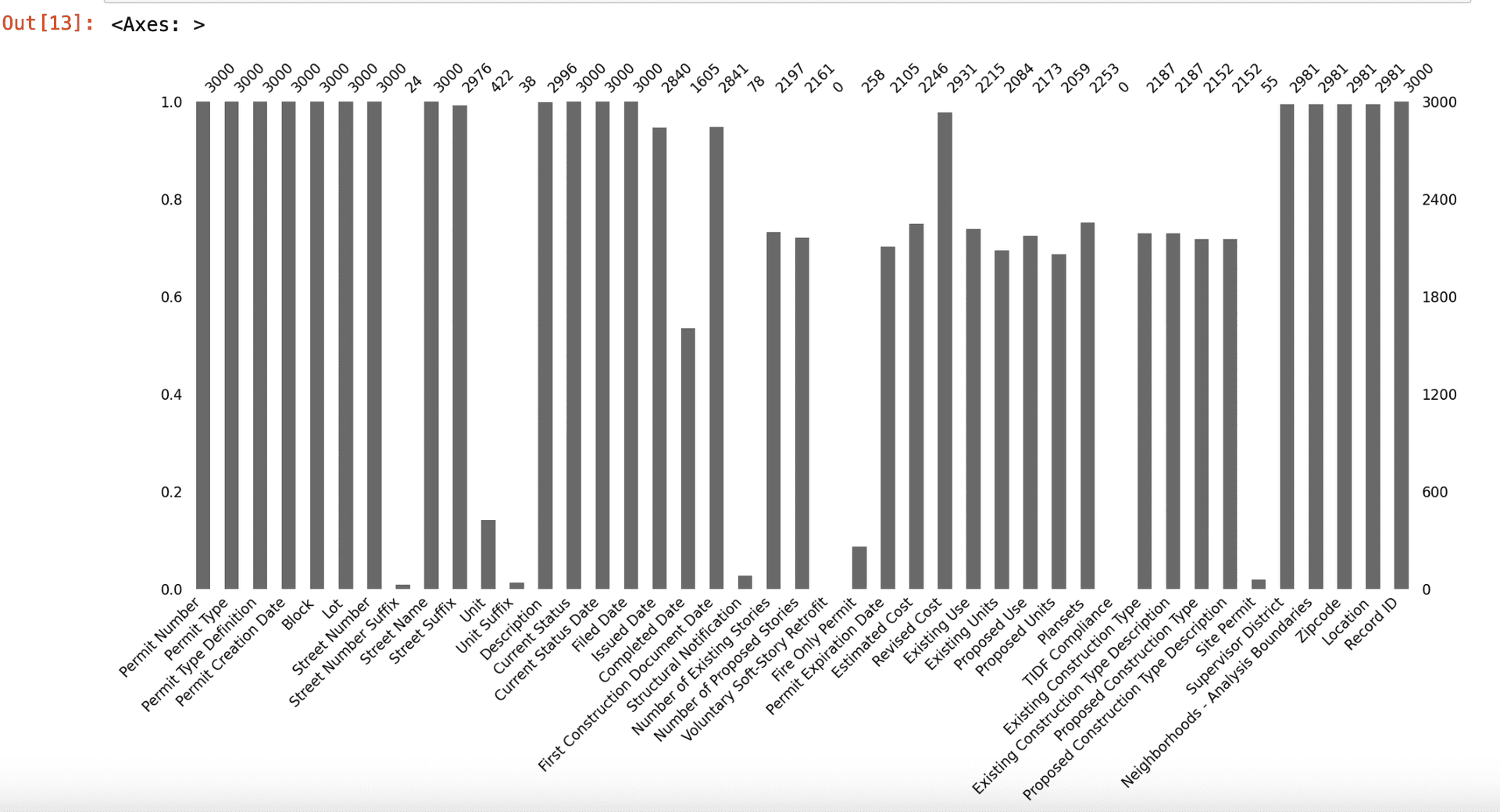
Why is it important? The bar plot provides a quick overview of the completeness of each column, highlighting columns with a high proportion of missing data.
5. Heatmap
The heatmap shows the correlation of missingness between different columns. A high correlation indicates that the presence of missing data in one column is related to the presence of missing data in another column.
msno.heatmap(df)Output:
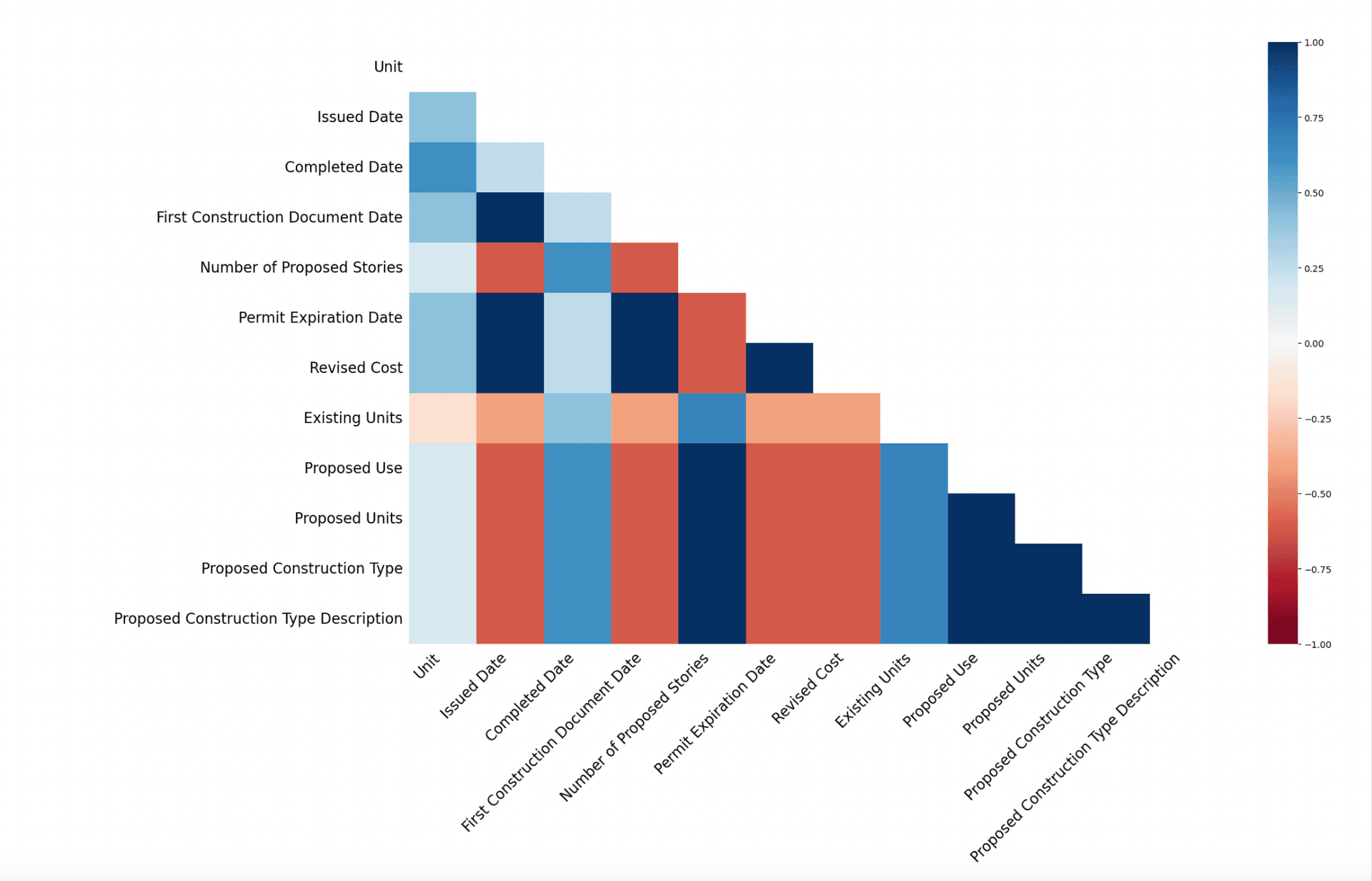
Why is it important? The heatmap helps identify relationships in missingness between columns, which can inform decisions on how to handle missing data, such as imputing missing values based on related columns.
6. Dendrogram
The dendrogram clusters columns based on the similarity of their missing data patterns.
msno.dendrogram(df)Output:
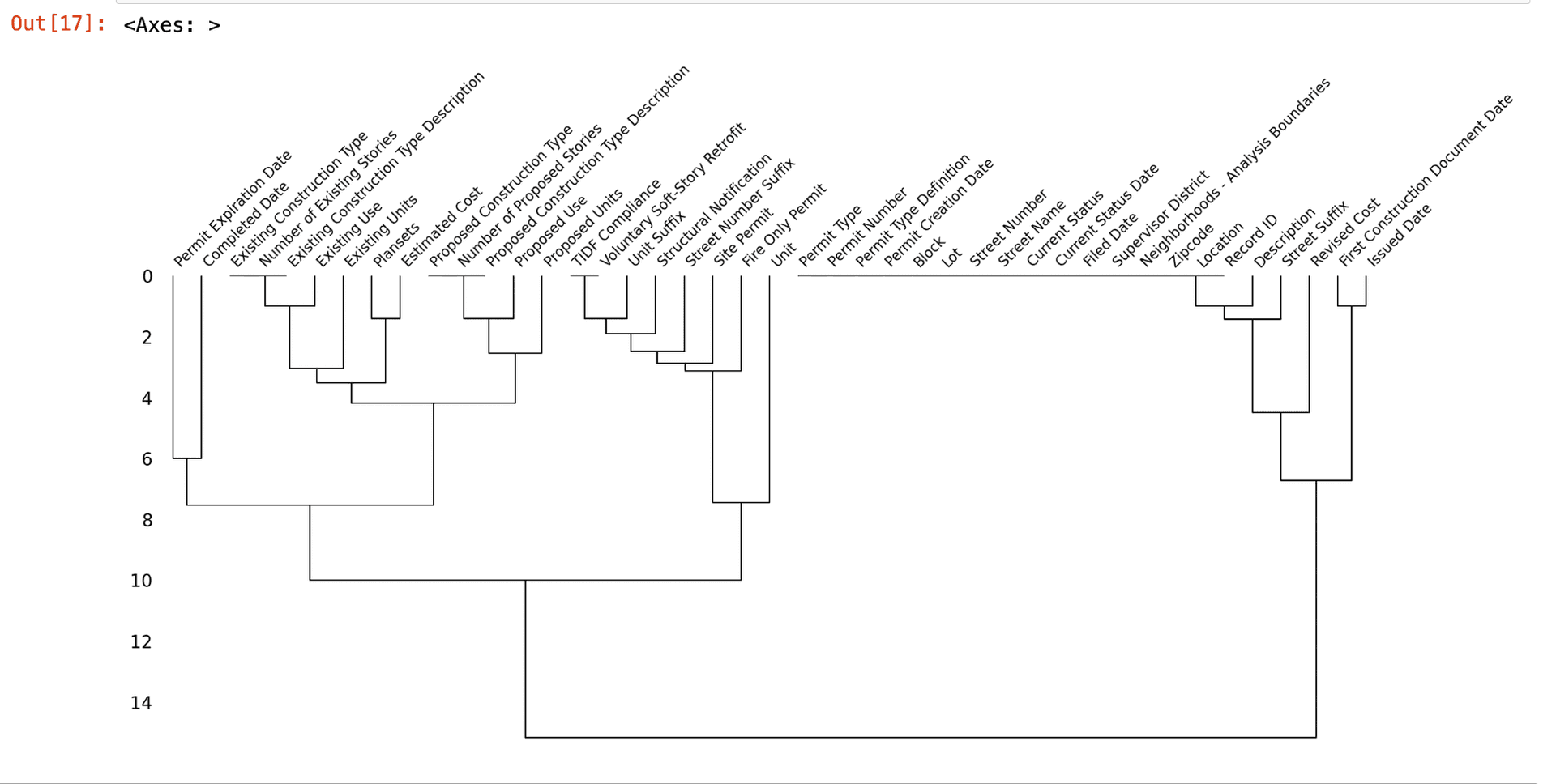
Why is it important? The dendrogram helps identify groups of columns with similar missing data patterns, which can be useful for imputation or for understanding the underlying structure of the data.
Conclusion
Visualizing missing data is a crucial step in data preprocessing. It helps understand the extent and pattern of missingness, guiding the choice of strategies for handling missing data. By using tools like missingno, you can quickly and effectively visualize and analyze missing data in your datasets.
References:
